Posts tagged "algorithms":
Why feature standardisation can improve classification results
In a previous post, we saw when and why feature normalisation before training a supervised classifier may needed. The main point of the post was about the fact that distance based classifiers need to operate on features which have similar dynamic ranges.
One thing we didn't discuss is why often things work better when the normalisation is done towards the [0-1] or the [-1,1] intervals rather than, for instance, the [0-100] range.
If you have used the SVM classifier, even with a linear kernel, using standardisation yields faster learning times and improved classification accuracy. Why is this the case?
SVM training usually uses optimisers (solvers) which are complex machines. Therefore, there may be several reasons for this behaviour, but one of them is the representation of floating point numbers in the computer. This representation is defined by an IEEE standard. In a nutshell, this representation gives different precisions to different ranges of values: the closer numbers are to 0, the higher the precision with which they are represented.
For a longer explanation, have a look at John Farrier's Demystifying Floating Point talk at CPPCon 2015. Farrier uses a visual example borrowed from an MSDN blog post that I am reproducing here:
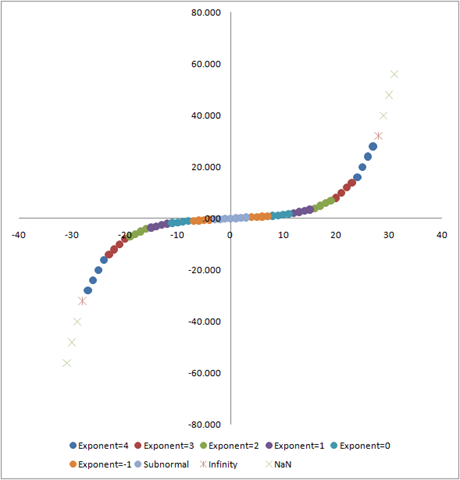
This plot means that the error with which a value is represented in the computer increases exponentially as a function of the value itself. It is therefore easy to understand that this representation error will make things difficult for optimisers even in the case where the cost function is quadratic, smooth and well conditioned.
Therefore, in order to make sure that the optimisation procedure benefits from accurate computations, rescaling feature values close to zero is useful.
Classification algorithms which do not optimise a cost function can also benefit from this rescaling. KNN classifiers, Self Organising Maps and many other algorithms using distances to select and sort will produce more accurate results.
On the other hand, if you use a tree-based classifier with a Gini purity index (like the Random Forest canonical implementation), rescaling is not needed, since the purity is computed over fractions which are already small numbers.
However, bear in mind that some tree-based classifiers use entropy (information gain) or other purity measures, like variance reduction which involve computations which may benefit from the increased precision obtained by the rescaling.
As a rule of thumb, in case of doubt, rescaling data will do no harm.
If you use the ORFEO Toolbox (and why wouldn't you?), the
TrainImagesClassifier and the ImageClassifier applications have
the option to provide a statistics file with the mean and standard
deviation of the features so they samples can be standardised. This
statistics file can be produced from your feature image by the
ComputeImagesStatistics application. You can therefore easily
compare the results with and without rescaling and decide what works
best in your case.
A simple thread pool to run parallel PROSail simulations
In the otb-bv we use the OTB versions of the Prospect and Sail models to perform satellite reflectance simulations of vegetation.
The code for the simulation of a single sample uses the ProSail simulator configured with the satellite relative spectral responses, the acquisition parameters (angles) and the biophysical variables (leaf pigments, LAI, etc.):
ProSailType prosail; prosail.SetRSR(satRSR); prosail.SetParameters(prosailPars); prosail.SetBVs(bio_vars); auto result = prosail();
A simulation is computationally expensive and it would be difficult to parallelize the code. However, if many simulations are going to be run, it is worth using all the available CPU cores in the machine.
I show below how using C++11 standard support for threads allows to easily run many simulations in parallel.
Each simulation uses a set of variables given in an input file. We parse the sample file in order to get the input parameters for each sample and we construct a vector of simulations with the appropriate size to store the results.
otbAppLogINFO("Processing simulations ..." << std::endl); auto bv_vec = parse_bv_sample_file(m_SampleFile); auto sampleCount = bv_vec.size(); otbAppLogINFO("" << sampleCount << " samples read."<< std::endl); std::vector<SimulationType> simus{sampleCount};
The simulation function is actually a lambda which will sequentially
process a sequence of samples and store the results into the simus
vector. We capture by reference the parameters which are the same for
all simulations (the satellite relative spectral responses satRSR
and the acquisition angles in prosailPars):
auto simulator = [&](std::vector<BVType>::const_iterator sample_first, std::vector<BVType>::const_iterator sample_last, std::vector<SimulationType>::iterator simu_first){ ProSailType prosail; prosail.SetRSR(satRSR); prosail.SetParameters(prosailPars); while(sample_first != sample_last) { prosail.SetBVs(*sample_first); *simu_first = prosail(); ++sample_first; ++simu_first; } };
We start by figuring out how to split the simulation into concurrent threads. How many cores are there?
auto num_threads = std::thread::hardware_concurrency(); otbAppLogINFO("" << num_threads << " CPUs available."<< std::endl);
So we define the size of the chunks we are going to run in parallel and we prepare a vector to store the threads:
auto block_size = sampleCount/num_threads; if(num_threads>=sampleCount) block_size = sampleCount; std::vector<std::thread> threads(num_threads);
Here, I choose to use as many threads as cores available, but this could be changed by a multiplicative factor if we know, for instance that disk I/O will introduce some idle time for each thread.
An now we can fill the vector with the threads that will process every block of simulations :
auto input_start = std::begin(bv_vec); auto output_start = std::begin(simus); for(size_t t=0; t<num_threads; ++t) { auto input_end = input_start; std::advance(input_end, block_size); threads[t] = std::thread(simulator, input_start, input_end, output_start); input_start = input_end; std::advance(output_start, block_size); }
The std::thread takes the name of the function object to be called,
followed by the arguments of this function, which in our case are the
iterators to the beginning and the end of the block of samples to be
processed and the iterator of the output vector where the results will
be stored. We use std::advance to update the iterator positions.
After that, we have a vector of threads which have been started
concurrently. In order to make sure that they have finished before
trying to write the results to disk, we call join on each thread,
which results in waiting for each thread to end:
std::for_each(threads.begin(),threads.end(), std::mem_fn(&std::thread::join)); otbAppLogINFO("" << sampleCount << " samples processed."<< std::endl); for(const auto& s : simus) this->WriteSimulation(s);
This may no be the most efficient solution, nor the most general
one. Using std::async and std::future would have allowed not to
have to deal with block sizes, but in this solution we can easily decide
the number of parallel threads that we want to use, which may be useful
in a server shared with other users.
Should we always normalize image features before classification?
The quick answer is of course not. But if I am writing this post is because I have been myself giving a rule of thumb to students for a while without explaining the details.
When performing image classification (supervised or unsupervised) I always tell students to normalize the features. This normalization can be for instance just standardization (subtract the mean and divide by the standard deviation), although other approaches are possible.
The goal of this normalization is being able to compare apples and oranges: many classification algorithms are based on a distance in the feature space, and in order to give equal weight to all features, they have to have similar ranges. For instance, if we have 2 features like the NDVI, which ranges from -1 to 1, and the slope of a topographic surface which could be between \(0^\circ\) and \(90^\circ\), the Euclidean distance would give much more weight to the slope and the NDVI values would not have much influence in the classification.
This is why the TrainImagesClassifier and the ImageClassifier
applications in the ORFEO Toolbox have the option to provide a
statistics file with the mean and standard deviation of the features
so they samples can be normalized.
This is needed for classifiers like SVM, unless custom kernels suited to particular sets of features are used.
Most OTB users have started using the Random Forest classifier since it was made available by the integration of the OpenCV Machine Learning module. And not long ago, someone told me that she did not notice any difference with and without feature normalization. Let's see why.
A Random Forest classifier uses a committee of decision trees. The decision trees split the samples at each node of the tree by thresholding one single feature. The learning of the classifier amounts basically at finding the value of the threshold at each node which is the optimum to split the samples.
The decision trees used by the Random Forest implementation in OpenCV use the Gini impurity in order to find the best split1. At any node of the tree during the learning, the samples are sorted in increasing order of the feature. Then all possible threshold values are used to split the samples into 2 sets and the Gini impurity is computed for every possible split. The impurity index does not use the values of the features, but only the labels of the samples. The values of the features are only used in order to sort the samples.
Any pre-processing of the features which is monotonic will not change the value of the Gini impurity and therefore will have no effect on the training of a Random Forest classifier.
Footnotes:
Actually, a variant of the Gini impurity is used, but this does not change the rationale here.
Data science in C?
Coursera is offering a Data Science specialization taught by professors from Johns Hopkins. I discovered it via one of their courses which is about reproducible research. I have been watching some of the video lectures and they are very interesting, since they combine data processing, programming and statistics.
The courses use the R language which is free software and is one the reference tools in the field of statistics, but it is also very much used for other kinds of data analysis.
While I was watching some of the lectures, I had some ideas to be implemented in some of my tools. Although I have used GSL and VXL1 for linear algebra and optimization, I have never really needed statistics libraries in C or C++, so I ducked a bit and found the apophenia library2, which builds on top of GSL, SQLite and Glib to provide very useful tools and data structures to do statistics in C.
Browsing a little bit more, I found that the author of apophenia has written a book "Modeling with data"3, which teaches you statistics like many books about R, but using C, SQLite and gnuplot.
This is the kind of technical book that I like most: good math and code, no fluff, just stuff!
The author sets the stage from the foreword. An example from page xii (the emphasis is mine):
" The politics of software
All of the software in this book is free software, meaning that it may be freely downloaded and distributed. This is because the book focuses on portability and replicability, and if you need to purchase a license every time you switch computers, then the code is not portable. If you redistribute a functioning program that you wrote based on the GSL or Apophenia, then you need to redistribute both the compiled final program and the source code you used to write the program. If you are publishing an academic work, you should be doing this anyway. If you are in a situation where you will distribute only the output of an analysis, there are no obligations at all. This book is also reliant on POSIX-compliant systems, because such systems were built from the ground up for writing and running replicable and portable projects. This does not exclude any current operating system (OS): current members of the Microsoft Windows family of OSes claim POSIX compliance, as do all OSes ending in X (Mac OS X, Linux, UNIX,…)."
Of course, the author knows the usual complaints about programming in C (or C++ for that matter) and spends many pages explaining his choice:
"I spent much of my life ignoring the fundamentals of computing and just hacking together projects using the package or language of the month: C++, Mathematica, Octave, Perl, Python, Java, Scheme, S-PLUS, Stata, R, and probably a few others that I’ve forgotten. Albee (1960, p 30)4 explains that “sometimes it’s necessary to go a long distance out of the way in order to come back a short distance correctly;” this is the distance I’ve gone to arrive at writing a book on data-oriented computing using a general and basic computing language. For the purpose of modeling with data, I have found C to be an easier and more pleasant language than the purpose-built alternatives—especially after I worked out that I could ignore much of the advice from books written in the 1980s and apply the techniques I learned from the scripting languages."
The author explains that C is a very simple language:
" Simplicity
C is a super-simple language. Its syntax has no special tricks for polymorphic operators, abstract classes, virtual inheritance, lexical scoping, lambda expressions, or other such arcana, meaning that you have less to learn. Those features are certainly helpful in their place, but without them C has already proven to be sufficient for writing some impressive programs, like the Mac and Linux operating systems and most of the stats packages listed above."
And he makes it really simple, since he actually teaches you C in one chapter of 50 pages (and 50 pages counting source code is not that much!). He does not teach you all C, though:
"As for the syntax of C, this chapter will cover only a subset. C has 32 keywords and this book will only use 18 of them."
At one point in the introduction I worried about the author bashing C++, which I like very much, but he actually gives a good explanation of the differences between C and C++ (emphasis and footnotes are mine):
"This is the appropriate time to answer a common intro-to-C question: What is the difference between C and C++? There is much confusion due to the almost-compatible syntax and similar name—when explaining the name C-double-plus5, the language’s author references the Newspeak language used in George Orwell’s 1984 (Orwell, 19496; Stroustrup, 1986, p 47). The key difference is that C++ adds a second scope paradigm on top of C’s file- and function-based scope: object-oriented scope. In this system, functions are bound to objects, where an object is effectively a struct holding several variables and functions. Variables that are private to the object are in scope only for functions bound to the object, while those that are public are in scope whenever the object itself is in scope. In C, think of one file as an object: all variables declared inside the file are private, and all those declared in a header file are public. Only those functions that have a declaration in the header file can be called outside of the file. But the real difference between C and C++ is in philosophy: C++ is intended to allow for the mixing of various styles of programming, of which object-oriented coding is one. C++ therefore includes a number of other features, such as yet another type of scope called namespaces, templates and other tools for representing more abstract structures, and a large standard library of templates. Thus, C represents a philosophy of keeping the language as simple and unchanging as possible, even if it means passing up on useful additions; C++ represents an all-inclusive philosophy, choosing additional features and conveniences over parsimony."
It is actually funny that I find myself using less and less class inheritance and leaning towards small functions (often templates) and when I use classes, it is usually to create functors. This is certainly due to the influence of the Algorithmic journeys of Alex Stepanov.
Footnotes:
Actually the numerics module, vnl.
Ben Klemens, Modeling with Data: Tools and Techniques for Scientific Computing, Princeton University Press, 2009, ISBN: 9780691133140.
Albee, Edward. 1960. The American Dream and Zoo Story. Signet.
Orwell, George. 1949. 1984. Secker and Warburg.
Stroustrup, Bjarne. 1986. The C++ Programming Language. Addison-Wesley.
Le jeu de la vie
C'est ainsi, Game of Life (GoL), qu'a été baptisé l'automate cellulaire imaginé par John Conway. Un automate cellulaire est un modèle où étant donné un état, on passe à l'état suivant en appliquant un ensemble de règles.
Dans le cas du GoL, le modèle est une grille (un quadrillage) composée de cellules qui sont, soit allumées (vivantes), soit éteintes (mortes). Les règles pour calculer l'état suivant sont simples1 :
- Une cellule morte possédant exactement trois voisines vivantes devient vivante (elle naît).
- Une cellule vivante possédant deux ou trois voisines vivantes le reste, sinon elle meurt.
En fonction de la taille de la grille et de la configuration initiale des cellules, l'évolution du jeu peut donner des résultats très intéressants. En voici un exemple tiré de Wikipédia :
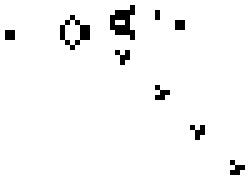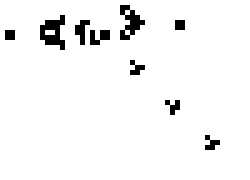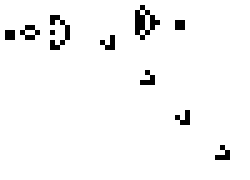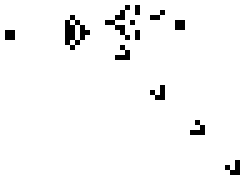
Au delà de son caractère amusant, le GoL présente des propriétés mathématiques très riches. Des structures stables et périodiques peuvent apparaître. Certaines ont même des noms très sympathiques : grenouilles, jardins d'Éden, etc.
Encore plus intéressant est le fait qu'il s'agit d'une machine de Turing universelle :
"il est possible de calculer tout algorithme pourvu que la grille soit suffisamment grande et les conditions initiales correctes"
et de là, il en découle, de par le problème de l'arrêt, qu'on ne peut pas prédire le comportement asymptotique de toute structure du jeu de la vie. Il s'agit d'un problème indécidable au sens algorithmique.
"Dire qu'un problème est indécidable ne veut pas dire que les questions posées sont insolubles mais seulement qu'il n'existe pas de méthode unique et bien définie, applicable d'une façon mécanique, pour répondre à toutes les questions, en nombre infini, rassemblées dans un même problème."2
On voit bien que, même une machine complètement déterministe et extrêmement simple, peut être imprédictible.
Il y en a qui seraient tentés de dire qu'une telle machine pourrait avoir du libre arbitre. Bien entendu, les gens sensés, auront un sourire narquois en entendant de tels propos. Une grille de morpion qui voudrait s'émanciper!
Si on revient sur le côté amusant du jeu, on pourrait avoir envie d'en faire un objet physique. Avec l'électronique bon marché pour les bricoleurs, il ne doit pas être difficile de brancher quelques (centaines de) LEDs et les piloter avec un Arduino contenant le programme avec les règles du GoL.
On pourrait même utiliser une webcam pour prendre une photo de l'environnement, la binariser et en faire ainsi la configuration initiale pour la grille.
De là, il est difficile d'échapper à la tentation du selfie pour initialiser le système. Est-ce que si on sourit sur la photo ça converge vers un jardin d'Éden3? Est-ce que si on fait la gueule ça génère des canons? Est-ce que si on prend Papi en photo ça nous fait des Mathusalems?
Et sans s'en rendre compte, on a construit un système physique qui réagit à l'expression d'un visage et dont l'état asymptotique est indécidable! C'est presque le niveau de développement social d'un bébé de quelques semaines. Et on peut le débrancher la nuit4!
Footnotes:
Comme d'habitude, Wikipédia est votre amie : http://fr.wikipedia.org/wiki/Jeu_de_la_vie .
En fait, c'est impossible par définition, mais bon …
Ce n'est pas encore aussi abouti que ce que Charlotte proposait la semaine dernière, mais on s'en approche.

{kind=link}