Posts tagged "free-software":
Use ChatGPT and feed the technofeudal beast
tl;dr1: Big Tech is deploying AI assistants on their cloud work-spaces to help you work better, but are you sure that what you produce using these tools falls under your copyright and not that of your AI provider?
Intro
Unless you have been living under a rock for the last few months, you have heard about ChatGPT and you probably have played with it. You may even make part of those who have been using it for somewhat serious matters, like writing code, doing your homework, or writing reports for your boss.
There are many controversies around the use of these Large Language Models (LLM, ChatGPT is not the only one). Some people are worried about white collar workers being replaced by LLM as blue collar ones were by mechanical robots. Other people are concerned with the fact that these LLM have been trained on data under copyright. And yet another set of people may be worried about the use of LLM for massive fake information spreading.
All these concerns are legitimate2, but there is another one that I don't see addressed and that, from my point of view is, at least, as important as those above: the fact that these LLM are the ultimate stage of proprietary software and user lock-in. The final implementation of technofeudalism.
Yes, I know that ChatGPT has been developed by OpenAI (yes open) and they just want to do good for humankind:
OpenAI’s mission is to ensure that artificial general intelligence (AGI)—by which we mean highly autonomous systems that outperform humans at most economically valuable work—benefits all of humanity. We will attempt to directly build safe and beneficial AGI, but will also consider our mission fulfilled if our work aids others to achieve this outcome.
But remember, ChatGPT is not open source and it is not a common good or a public service, as opposed to Wikipedia, for instance.
The evolution of user lock-in in software
Proprietary software is software that comes with restrictions on what the user can do with it.
A long time ago, software used to come in a box, on floppy disks, cartridges or CD-ROM. The user put the disk on the computer and installed it. There was a time, were, even if the license didn't allow it, a user could lend the disk to friends so they could install it on their own computers. At that time, the only lock-in that the vendor could enforce was that of proprietary formats: the text editor you bought would store your writing in a format that only that software could write.
In order to avoid users sharing a single paid copy of the software, editors implemented artificial scarcity: a registration procedure. For the software to work, you needed to enter a code to unlock it. With the advent of the internet, the registration could be done online, and therefore, just one registration per physical box was possible. This was a second lock-in. Of course this was not enough, and editors implemented artificial obsolescence: expiring registrations. The software could stop working after a predefined period of time and a new registration was needed.
Up to this point, clever users always found a way to unlock the software, because software can be retro-engineered. In Newspeak, this is called pirating.
The next step was to move software to the cloud (i.e. the editor's computers). Now, you didn't install the software on your computer, you just connected to the editor's service and worked on your web browser. This allowed the editor to terminate your license at any time and even to implement pay-per-use plans. Added to that, your data was hosted on their servers. This is great, because you always have access to the most recent version of the software and your data is never lost if your computer breaks. This is also great for the editor, because they can see what you do with their software and have a peek at your data.
This software on the cloud has also allowed the development of the so-called collaborative work: several people editing the same document, for instance. This is great for you, because you have the feeling of being productive (don't worry, it's just a feeling). This is great for the editor, because they see how you work. Remember, you are playing a video-game on their computer and they store every action you do3, every interaction with your collaborators.
Now, with LLM, you are in heaven, because you have suggestions on how to write things, you can ask questions to the assistant and you are much more productive. This is also great for the editor, because they now not only know what you write, how you edit and improve your writing, but they also know what and how you think. Still better, your interactions with the LLM are used to improve it. This is a win-win situation, right?
How do LLM work?
The short answer is that nobody really knows. This is not because there is some secret, but rather because they are complex and AI researchers themselves don't have the mathematical tools to explain why they work. We can however still try to get a grasp of how they are implemented. You will find many resources online. Here I just show off a bit. You can skip this section.
LLM are a kind of artificial neural network, that is, a machine learning system that is trained with data to accomplish a set of tasks. LLM are trained with textual data, lots of textual data: the whole web (Wikipedia, forums, news sites, social media), all the books ever written, etc. The task they are trained to perform is just to predict the next set of words given a text fragment. You give the beginning of a sentence to the system and it has to produce the rest of it. You give it a couple of sentences and it has to finish the paragraph. You see the point.
What does "training a system" mean? Well, this kind of machine learning algorithm is just a huge mathematical function which implements millions of simple operations of the kind \(output = a \times input + b\). All these operations are plugged together, so that the output of the first operation becomes the input of the second, etc. In the case of a LLM, the very first output is the beginning of the sentence that the system has to complete. The very last output of the system is the "prediction" of the end of the sentence. You may wonder how you add or multiply sentences? Well, words and sentences are just transformed to numbers with some kind of dictionary, so that the system can do its operations. So to recap:
- you take text and transform it to sequences of numbers;
- you take these numbers and perform millions of operations like \(a\times input + b\) and combine them together;
- you transform back the output numbers into text to get the answer of the LLM.
Training the model means finding the millions of \(a\) and \(b\) (the parameters of the model) that perform the operations. If you don't train the model, the output is just rubbish. If you have enough time and computers, you can find the good set of parameters. Of course, there is a little bit of math behind all this, but you get the idea.
Once the model is trained, you can give it a text that it has never encountered (a prompt) and it will produce a plausible completion (the prediction). The impressive thing with these algorithms is that they do not memorize the texts used for training. They don't check a database of texts to generate predictions. They just apply a set of arithmetic operations that work on any input text. The parameters of the model capture some kind of high level knowledge about the language structure.
Well, actually, we don't know if LLM do not memorize the training data. LLM are to big and complex to be analyzed to check that. And this is one of the issues related to copyright infringement that some critics have raised. I am not interested in copyright here, but this impossibility to verify that training data can't appear at the output of a LLM will be of crucial importance later on.
Systems like ChatGPT, are LLM that have been fine-tuned to be conversational. The tuning has been done by humans preparing questions and answers so that the model can be improved. The very final step is RLHF: Reinforcement Learning from Human Feedback. Once the model has been trained and fine-tuned, they can be used and their answers can be rated by operators in order to avoid that the model spits out racist comments, sexist texts or anti-capitalist ideas. OpenAI who, remember, just want to do good to humankind abused under-payed operators for this task.
OK. Now you are an expert on LLM and you are not afraid of them. Perfect. Let's move on.
Technofeudalism
If producing a LLM is not so complex, why aren't we all training our own models? The reason is that training a model like GPT-3 (the engine behind ChatGPT) needs about 355 years on a single NVIDIA Tesla V100 GPU4, so if you want to do this in something like several weeks you need a lot of machines and a lot of electricity. And who has the money to do that? The big tech companies.
You may say that OpenAI is a non profit, but Wikipedia reminds us that Microsoft provided OpenAI with a $1 billion investment in 2019 and a second multi-year investment in January 2023, reported to be $10 billion. This is how LLM are now available in Github Copilot (owned by Microsoft), Bing and Office 365.
Of course, Google is doing the same and Meta may also be doing their own thing. So we have nothing to fear, since we have the choice. This is a free market.
Or maybe not. Feudal Europe was not really a free market for serfs. When only a handful of private actors have the means to build this kind of tools we become dependent on their will and interests. There is also something morally wrong here: LLM like ChatGPT have been trained on digital commons like Wikipedia or open source software, on all the books ever written, on the creations of individuals. Now, these tech giants have put fences around all that. Of course, we still have Wikipedia and all the rest, but now we are being told that we have to use these tools to be productive. Universities are changing their courses to teach programming with ChatGPT. Orange is the new black.
Or as Cédric Durand explains it:
The relationship between digital multinational corporations and the population is akin to that of feudal lords and serfs, and their productive behavior is more akin to feudal predation than capitalist competition.
[…]
Platforms are becoming fiefs not only because they thrive on their digital territory populated by data, but also because they exercise a power lock on services that, precisely because they are derived from social power, are now deemed indispensable.5
When your thoughts are not yours anymore
I said above that I am not interested in copyright, but you might be. Say that you use a LLM or a similar technology to generate texts. You can ask ChatGPT to write a poem or the lyrics of a song. You just give it a subject, some context and there it goes. This is lots of fun. The question now is: who is the author of the song? It's clearly not you. You didn't create it. If ChatGPT had some empathy, it could give you some kind of co-authorship, and you should be happy with that. You could even build a kind of Lennon-McCartney joint venture. You know, many of the Beatles' songs were either written by John or Paul, but they shared the authorship. They were good chaps. Until they weren't anymore.
You may have used Dall-E or Stable Diffusion. These are AI models which generate images from a textual description. Many people are using them (they are accessible online) to produce logos, illustrations, etc. The produced images contain digital watermarking. This is a kind of code which is inserted in the image and that is invisible to the eye. This allows to track authorship. This can be useful to prevent deep fakes. But this can also be used to ask you for royalties if ever the image generates revenue.
Watermarking texts seems impossible. At the end of the day, a text is just a sequence of characters, so you can't hide a secret code in it, right? Well, wrong. You can generate a text with some statistical patterns. But, OK, the technology does not seem mature and seems easy to break with just small modifications. You may therefore think that there is no risk of Microsoft or Google suing you for using their copyrighted material. Well, the sad thing is that you produced your song using their software on their computers (remember, SaaS, the cloud), so they have the movie showing what you did.
This may not be a problem if you are just writing a song for a party or producing an illustration for a meme. But many companies will soon start having employees (programmers, engineers, lawyers, marketers, writers, journalists) producing content with these tools on these platforms. Are they willing to share their profits with Microsoft? Did I tell you about technofeudalism?
Working for the man
Was this response better or worse? This is what ChatGPT asks you if you tell it to regenerate a response. You just have to check one box: better, worse, same. You did it? Great! You are a RLHFer6. This is why ChatGPT is free. Of course, it is free for the good of humankind, but you can help it to get even better! Thanks for your help. By the way, Github Copilot will also get better. Bing also will get better. And Office 365 too.
Thanks for helping us feed the beast.
Cheers.
Footnotes:
Abstract for those who have attention deficit as a consequence of consuming content on Twitter, Instragram and the like.
Well, at least if you believe in intellectual property, or think that bullshit jobs are useful or that politicians and companies tell the truth. One has to believe in something, I agree.
Yes, they do. This is needed to being able to revert changes in documents.
"My" translation. You have an interesting interview in English here https://nymag.com/intelligencer/2022/10/what-is-technofeudalism.html.
Reinforcement Learning from Human Feedback. I explained that above!
Modernisation du SI, suites bureautiques dans le nuage et protection des secrets industriels
Les DSI1 des moyennes et grandes entreprises sont fatiguées de devoir maintenir et mettre à jour des centaines ou des milliers de postes de travail alors que l’informatique n’est pas cœur de métier de la boîte2. En plus, les informaticiens compétents ayant une bonne hygiène corporelle sont difficiles à trouver.
La réponse est évidemment de se tourner vers les « solutions » en ligne, le SaaS (Software as a Service), le cloud. C’est simple : le poste utilisateur peut se limiter à un terminal avec un navigateur internet qui se connectera aux serveurs de Microsoft ou de Google (les 2 fournisseurs principaux). Plus besoin d’installation locale de suite Office, plus besoin de mise à jour ou de montée en version, plus besoin de sauvegardes. C’est le fournisseur qui s’occupe de tout, les logiciels tournent chez lui et les documents produits sont aussi hébergés sur ses machines.
C’est simple, c’est dans le nuage : c’est la modernisation du SI !
Cependant, certaines entreprises sont trop à cheval sur la propriété intellectuelle, la souveraineté numérique et même la PPST ou le RGPD. Elles pourraient donc être réticentes à adopter ce type de solution. En effet, il peut être délicat de stocker des informations confidentielles sur des serveurs que l’on ne maîtrise pas. Mais comment rester compétitif face à ceux qui sont disruptifs, bougent vite et qui ne se laissent pas embêter par des amish ?
D’après les fournisseurs, il n’y a pas de crainte à avoir, car les solutions proposées permettent d’activer le chiffrement côté client. Ceci veut dire que les flux de données entre le poste utilisateur et les serveurs du fournisseur sont chiffrés cryptographiquement par une clé que seulement le client possède. La conséquence est que les documents stockés chez le fournisseur sont illisibles pour lui, car il n’a pas la clé.
Nous voilà rassurés. C’est sans doute pour cela que Airbus utilise Google Workspace3 ou que Thales utilise Microsoft 365. Par ailleurs, Thales est partenaire de Microsoft pour le développement des techniques de chiffrage. Cocorico !
Du coup, les appels d’offres de l’État français pour des suites bureautiques souveraines semblent ne pas avoir de sens. Surtout, qu’il y a aussi des partenariats franco-américains de « cloud de confiance » qui vont bientôt voir le jour. Mais il reste des questions à se poser. Par exemple, on peut lister ces points de vigilance :
- Le chiffrement côté client n’est pas fiable. J’y reviens ci-dessous.
- L’extraterritorialité du droit américain peut imposer aux fournisseurs américains de mettre en œuvre « un espionnage paré des vertus de la légalité ».
- Le fournisseur peut fermer l’accès du client à tout moment : plus d’e-mail, plus de tableur excel, plus de ChatGPT qui nous aide à écrire des rapports que personne ne lit.
Pourquoi le chiffrement côté client n’est-il pas fiable ? Pour commencer, ce chiffrement n’est pas complet : beaucoup d’informations sont accessibles en clair pour le fournisseur. Par exemple, les noms des documents, les entêtes des e-mails, les listes des participants à des réunions, etc. Les flux vidéo et audio seraient chiffrés, mais, même le fournisseur officiel de chiffrement pour Microsoft écrit ça dans les invitations à des visioconférences sur Teams :
Reminder: No content above "THALES GROUP LIMITED DISTRIBUTION” / “THALES GROUP INTERNAL" and no country eyes information can be discussed/presented on Teams.
Petite explication de « country eyes » par ici4.
Mais il y a un autre aspect plus intéressant concernant le chiffrement côté client. Ce chiffrement est fait par un logiciel du fournisseur pour lequel le client n’a pas le code source. Donc il n’y a aucune garantie que ce chiffrement est fait ou qu’il est fait proprement. On pourrait rétorquer que les logiciels peuvent être audités : le fournisseur vous laisse regarder le code ou il vous permet d’étudier le flux réseau pour que vous soyez rassuré. On peut répondre : dieselgate, c’est-à-dire, il n’y a aucune garantie que le logiciel se comporte de la même façon pendant l’audit que le reste du temps. De plus, vu que le fournisseur gère les mises à jour du logiciel, il n’y a pas de garantie que la version auditée corresponde à celle qui est vraiment utilisée.
Il semblerait donc que la vraie « solution » soit d’héberger ses propres données et logiciels et que le code source de ces derniers soit disponible. Le cloud suzerain5 n’est pas une fatalité.
Footnotes:
Direction des Systèmes d’Information, le département informatique.
Il y a aussi des entreprises dont l’informatique est le cœur de métier qui font aussi ce que je décris par la suite.
On a fait un long chemin depuis que Airbus portait plainte pour espionnage industriel de la part des USA. Depuis Snowden, on sait que la NSA s’abreuve directement chez les GAFAM.
"A surveillance alliance is an agreement between multiple countries to share their intelligence with one another. This includes things like the browsing history of any user that is of interest to one of the member countries. Five eyes and Fourteen eyes are two alliances of 5 and 14 countries respectively that agree to share information with one another wherever it is mutually beneficial. They were originally made during the cold war as a means of working together to overcome a common enemy (the soviet union) but still exist today." https://www.securitymadesimple.org/cybersecurity-blog/fourteen-eyes-surveillance-explained
Non, pas de coquille ici.
The end of e-mail
e-mail is great
e-mail is a great form of communication.
For starters, it is asynchronous, which means that one can choose to deal with it when desired and not to be victim of unwanted interruptions (unlike phone calls).
e-mails can be of any length, from just one word in the subject line and an empty body (unlike a letter), up to several pages of arguments and ideas. They can be accompanied by attached documents and richly formatted1 (unlike the limits of SMS or some «social media» platforms).
e-mails have some kind of permanence, since they can be stored by the sender or the receiver as they want (unlike most modern «social media»).
e-mail is decentralized, in the sense that anybody can have their own server and send and receive e-mails without going through a central server or authority (unlike most of the means of electronic communications we use today, be it SMS, WhatsApp, etc.). e-mail can be considered as the first service in the Fediverse.
e-mail also allows to personalize how one wants to appear on the internet, since an e-mail address can show the belonging to a group, a company, just one's own name or even a chosen nickname.
e-mail sucks
Of course, most people have learned to hate e-mail with an attitude which has become rather hipster.
- We get lots of e-mail (but much less than what we get on Twitter, Instagram, WhatsApp, etc.)
- Lots of e-mail is spam (not unlike the ads one gets on all other media)
- Long e-mail threads with many people in CC are close to spam (not unlike Twitter threads)
All these issues can be solved by using a good e-mail client or MUA which allows us to filter and archive messages to suit our preferences (unlike the algorithms implemented by Twitter, Facebook and even Gmail, which choose what one can see). We can also have a good electronic hygiene by unsubscribing from useless newsletters, implementing «Inbox zero» (if that works for us), shutting off e-mail notifications and using different e-mail addresses for different purposes2.
A monopolistic view of e-mail
Many have predicted, wanted and even worked towards the end of e-mail. You may remember Wave, a Google project presented as the perfect replacement for e-mail. It was discontinued after a very short life, then the Apache Foundation tried to resuscitate it, but it was finally abandoned.
Google was criticized for trying to implement this e-mail substitute as a way to capture all those electronic communications which where happening between people not using Google services. Indeed, despite the popularity of Gmail, both as an e-mail provider (with lots of storage for free) and as an e-mail client (with a very good anti-spam filter, and other useful features to deal with lots of e-mail), this service uses the standard e-mail protocol and therefore, it is difficult to have a monopoly on it.
Why would Google want to have all the e-mail on the internet go through their servers? Because being able to parse and inspect all these messages allows to extract lots of information which is useful to train AI models which in turn can be used to understand what people think, want and need3. Then one can select which ads to show them and how to keep them «engaged» in their platform.
I am picking on Google because it was the first player on this game, but Microsoft is doing the same with the Office365 platform, where Outlook is the Gmail equivalent.
The network effect and the silo
Just providing a complete platform with an online office suite, e-mail (server, storage and client) does not seem enough to force all users to stay permanently on the platform. What should Google and Microsoft do to get people to do all their electronic communications on their platforms?
Until now, they have succeeded in capturing lots of users: nearly everybody has a Google account because of Android and YouTube; and an increasing number of people, at least in the enterprise and academic sectors, are Office365 users because of the «need» of collaborative distributed editing (think SharePoint and the move of Microsoft Office itself to the cloud).
If a large number of business and universities have moved to cloud services like G-suite and Office365, this means that many e-mail messages have a receiver on these platforms. What can these platforms do to get more users? The easiest thing is to make communications with users outside these platforms difficult. For instance, redirect to spam all e-mails coming from domains which are not linked to the platforms. Google will accept messages from Microsoft servers and vice-versa, but will likely flag as spam messages coming from other sources.
Spam is your friend
Fewer and fewer people maintain their own e-mail servers. It is not a matter of lack of technical skills. Easy solutions like Mail-in-a-Box exist, so nearly anybody can install their own server. The problem is that these servers are often blacklisted and the messages they sent are trashed by the receivers4. This makes many sysadmins choose e-mail services hosted by cloud providers, like Gandi, OVH, or Ionos in Europe.
Unfortunately, some of those, like OVH, have chosen to replace the technology they used which was based on Free Software (postfix or sendmail, etc.) by Exchange. Are they loosing their technical skills and prefer to use a commercial product with commercial support? Or are they choosing a solution which is less likely to be flagged as spam? After all, a Russian spammer will use free software instead of buying a Microsoft license.
Regardless, these providers will have a hard time competing with complete integrated solutions as those from Google or Microsoft5.
Break the standards
Now that everybody uses Google or Microsoft servers, there is still one thing that bothers these companies. As e-mail uses a set of open protocols (SMTP for sending and IMAP or POP for getting the messages from the server), there is still the possibility to access Google and Microsoft servers with clients running locally on the users computers. It is therefore impossible for the provider to display ads or monitor how the user interacts with e-mail. This is a loss of potential revenue.
Both Google and Microsoft have announced that they will be shutting down the standard user authentication for SMTP and IMAP. The only way to send and receive e-mail will be to implement an authentication which needs to register the client application with a secret token which may change periodically. That means that only applications for which Google and Microsoft will have given their blessing will be able to communicate with Gmail and Outlook accounts.
Of course, getting a Free Software e-mail client registered with Google or Microsoft should be possible, but their terms of service forbid making public the registration token, which means that it can not be embedded in the free software. Thunderbird and KMail seem to have gotten an exception, but for how long?
The end of e-mail?
So that is a nifty theory about evil corporations working to destroy our dear internet. I am probably wrong and even a little paranoid here, but the fact is that it is increasingly difficult to self-host an e-mail server and use local e-mail clients.
If you have a different point of view or any ideas on how to preserve e-mail as a decentralized and open means of electronic communication, please get in touch. Contact information is available at the bottom of the page.
The sad thing is that most people don't care about these issues. Most people think that the internet is the web. From those, the majority things that the internet is Google or Facebook.
Even most people who are into politics don't care or don't understand. Left-wing anti-capitalists are on Facebook and use Gmail and then they complain when they are censored. Conservative patriotic nationalists in Europe live in Microsoft environments to write and discuss about sovereignty. What a joke!
Footnotes:
Although there are drawbacks to that: HTML e-mail is usually twice the volume of a plain text one and it is often used for phishing attacks.
Personal and professional, of course, but also having a specific address to give to any commercial entity pretending to need our e-mail contact.
"I think of Google as a set of overlapping things. It's a consumer platform, consumer phenomenon of which search is its fundamental activity, but there are many other things you can do than search… I think of Google as an advertising company who services the broader advertising industry in the ways that you know." Eric Schmidt
If Gmail has the best anti-spam filter, how come there are so may false positives?
Again, free software solutions exist, like those based on Nextcloud and the associated ecosystem of applications, but most business and universities choose to go with Google and Microsoft instead of fostering in-house skills or supporting local companies which can provide maintenance for these solutions.
Sympathy for the Evil: let's help improve Google Earth Engine
Please allow me to introduce a couple of ideas which should help improve the user experience on the GEE platform. I know that Google, a company of wealth and taste, has an impressive record on providing services with outstanding features. They have the best search engine, the best web mail application and the best web browser1.
But these services and tools are targeted to non expert users. With GEE, Google is addressing a complete different audience: scientists, or I should say Scientists. These are clever people with PhD's! Therefore, in order to keep them satisfied Google will have to make an extra effort. One could think that scientists can easily be fooled because, for instance, they agree with giving away to private companies the results of research funded with tax payer money2. Or because they accept to be evaluated by how many times their tweets are liked3. Seeing scientists like this would be a mistake. They are very demanding users who only want to use the best tools4.
But Google has the technology needed to attract this smarter-than-the average users. Here go some ideas which could make GEE the best platform for producing impactful research using remote sensing data.
Executable papers
I think that it would be nice to introduce some literate programming facilities in the code editor. This could be similar to what can be done with Emacs org-mode's Babel or Knitr for the R programming language. This would allow to directly write scientific papers on the GEE editor and keep together notes, formulas, code and charts. Of course, exporting to Google Docs would be also very useful so that results can be integrated in slides or spreadsheets.
The possibility of citing bibliographic references should also be integrated in the editor. I suppose that a Google Scholar search function would not be difficult to add. Oh, yes, and Google Books also, by the way. Actually, using the same technology Google uses to insert advertisements in search results or in Gmail, it would be possible to automatically suggest references based on what the user is writing.
In these suggestions, papers produced using GEE could come first, since they are better. Papers written by people in the author's Google contacts list could also be promoted: good friends cite friends and the content of e-mails should help the algorithms determine if they are collaborators or competitors. But let's trust Google to find the algorithm which will make the best suggestions.
Many software development environments have code completion. In the case of GEE the technology5 would be much more powerful since all the code written by all scientists could be used to make suggestions. The same technology could be used to suggest completions for the text of the papers. We all know how boring is writing again and again the same "introduction" and "materials and methods" sections. Google algorithms could introduce some randomness and even compute a plagiarism score to help us make sure that we comply with the scientific literature standards. Of course, the "Conclusions" section could be automatically produced from the results using Google's AI technology.
It would also be nice to have some kind of warning if the user was designing an experiment or a processing chain that somebody else had already done. So some kind of message like "this has already been done" together with the link to the corresponding paper would be great. Also, automatic checking for patent infringement would be useful. Again, Google has all we need. In this case, the warning message could be "I can't let you do that Dave".
Massive peer review
The executable paper written using what has been described above could be made available through Google Plus as a pre-print. Actually, nobody would call that a "pre-print", but rather a paper in beta. All people in the author's circles could be able to comment on it and, most importantly, give a +1 as a warrant of scientific quality. This approach could quickly be replaced by a more reliable one. Using deep learning (of course, what else?) applied to the training data base freely generated by GEE early adopters, Google could propose an unbiased system for paper review which would be much faster than the traditional peer review approach. The h-index should be abandoned and replaced by the paper-rank metric.
Funding research
Thanks to GEE, doing remote sensing based science will become much cheaper. Universities and research centres won't need to buy expensive computers anymore. Instead, just one Chromebook per person will be enough. Actually, not even offices will be needed, since WiFi is free at Starbucks. Lab meetings can be cheaply replaced by Google Hangouts.
However, scientists will still need some funding, since they can't live on alphaet soup and coffee is still not free at Starbucks. Google has a grant programme for scientists, but this is somewhat old school: real people have to review proposals and even worse, scientists have to spend time writing them.
Again, Google has the technology to help here: "AdSense is a free, simple way to earn money by placing ads on your website." Scientists who would allow ads on their papers, could make some revenue.
Conclusion
I know that in this post I have given away many ideas which could be used to get venture capital for a start-up which could make lots of money, but this would be really unfair, because all this would not be possible without:
- Google Earth Engine
- Gmail
- Google Chrome
- Google Docs
- Google Scholar
- Google Books
- Google Patents
- Google Plus
- +1
- Chromebook
- Google Starbucks
- Google Hangouts
- AdSense
- Google's Youtube
Don't forget that the mission statement of GEE is "developing and sharing new digital mapping technology to save the world". And anyway, section 4.3 of GEE Terms of Service says6:
Customer Feedback. If Customer provides Google Feedback about the Services, then Google may use that information without obligation to Customer, and Customer hereby irrevocably assigns to Google all right, title, and interest in that Feedback.
Footnotes:
They used to have the best RSS reader, but they killed it http://chromespot.com/2013/06/06/google-reader-shutting-down/.
Is Google Earth Engine Evil?
More than for any other post in this blog, the usual disclaimer applies here.
Let's face it: what Google has implemented with the Earth Engine is very appealing since it is the first solution for Earth Observation data exploitation which concentrates all the open access EO data, the computing resources and the processing algorithms. This is the Remote Sensing Scientist dream. Or is it?
Talks and posters at ESA Living Planet Symposium this week show that an increasing number of people are using GEE to do science. One of the reasons put forward is the possibility of sharing the scripts, so that other people can reproduce the results. This is, in my opinion, an incorrect statement. Let's have a look at a definition of reproducible research:
An article about computational science in a scientific publication is not the scholarship itself, it is merely advertising of the scholarship. The actual scholarship is the complete software development environment and the complete set of instructions which generated the figures. —D. Donoho
One important term here is complete. When you use GEE, or any other non free software like Matlab, even if you share your scripts, the core of the algorithms you are using is just a black box which can't be inspected. Actually, the case of GEE is even worse than the one of non free software running locally. Google could change the implementation of the algorithms and your scripts would yield different results without you being able to identify why. Do you remember the "Climategate"? One of the main conclusions was:
… the reports called on the scientists to avoid any such allegations in the future by taking steps to regain public confidence in their work, for example by opening up access to their supporting data, processing methods and software, and by promptly honouring freedom of information requests.
During one of my presentations at the Living Planet Symposium I decided to warn my fellow remote sensers about the issues with GEE and I put a slide with a provocative title. The room was packed with more than 200 people and somebody tweeted this:

So it seems I was able to get some attention, but a 2-minute slide summarised in a 140 character tweet is not the best medium to start this discussion.
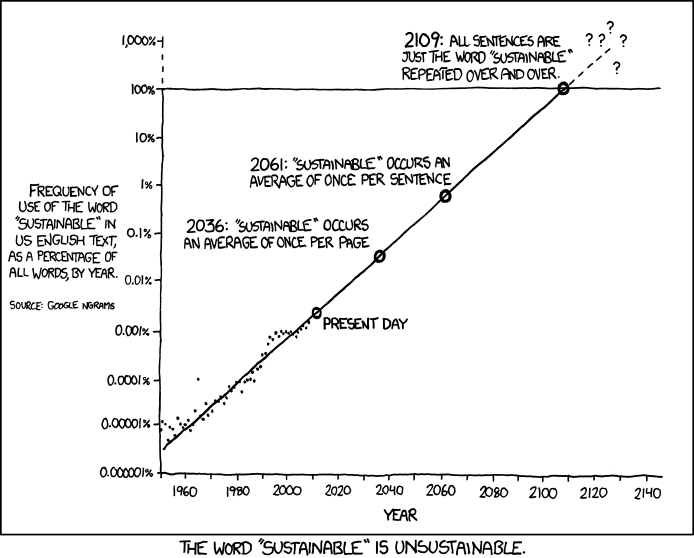
As I said during my presentation, I fully understand why scientists are migrating towards GEE and I don't blame them. Actually, there is nobody to blame here. Not even Google. But in the same way that, after many years of scientists using non free software and publishing in non open access journals, we should take a step back and reflect together about how we want to do Earth Observation Science in a sustainable (which is the perenniality of GEE?) and really open way.
What I was suggesting in the 3 last bullet points in my slide (which don't appear in the tweeted picture1) is that we should ask ESA, the European Commission and our national agencies to join efforts to implement the infrastructure where:
- all data is available;
- and every scientist can log in and build and share libre software for doing science.
And this is much cheaper than launching a satellite.
This is not to criticise what the agencies are doing. ESA's Thematic Exploitation Platforms are a good start. CNES is developing PEPS and Theia which together are a very nice step forward. But I think that a joint effort driven by users' needs coming from the EO Science community would help. So let's speak up and proceed in a constructive way.
Installing OTB has never been so easy
You've heard about the Orfeo Toolbox library and its wonders, but urban legends say that it is difficult to install. Don't believe that. Maybe it was difficult to install, but this is not the case anymore.
Thanks to the heroic work of the OTB core development team, installing OTB has never been so easy. In this post, you will find the step-by-step procedure to compile OTB from source on a Debian 8.0 Jessie GNU/Linux distribution.
Prepare the user account
I assume that you have a fresh install. The procedure below has been tested in a virtual machine running under VirtualBox. The virtual machine was installed from scratch using the official netinst ISO image.
During the installation, I created a user named otb that I will use
for the tutorial below. For simplicity, I give this user root
privileges in order to install some packages. This can be done as
follows. Log in as root or use the command:
su -
You can then edit the /etc/sudoers file by using the following
command:
visudo
This will open the file with the nano text editor. Scroll down to
the lines containing
# User privilege specification root ALL=(ALL:ALL) ALL
and copy the second line and below and replace root by otb:
otb ALL=(ALL:ALL) ALL
Write the file and quit by doing C^o ENTER C^x.
Log out and log in as otb. You are set!
System dependencies
Now, let's install some packages needed to compile OTB. Open a
terminal and use aptitude to install what we need:
sudo aptitude install mercurial \ cmake-curses-gui build-essential \ qt4-dev-tools libqt4-core \ libqt4-dev libboost1.55-dev \ zlib1g-dev libopencv-dev curl \ libcurl4-openssl-dev swig \ libpython-dev
Get OTB source code
We will install OTB in its own directory. So from your $HOME
directory create a directory named OTB and go into it:
mkdir OTB
cd OTB
Now, get the OTB sources by cloning the repository (depending on your network speed, this may take several minutes):
hg clone http://hg.orfeo-toolbox.org/OTB
This will create a directory named OTB (so in my case, this is
/home/otb/OTB/OTB).
Using mercurial commands, you can choose a particular version or you can go bleeding edge. You will at least need the first release candidate for OTB-5.0, which you can get with the following commands:
cd OTB hg update 5.0.0-rc1 cd ../
Get OTB dependencies
OTB's SuperBuild is a procedure which deals with all external libraries needed by OTB which may not be available through your Linux package manager. It is able to download source code, configure and install many external libraries automatically.
Since the download process may fail due to servers which are not
maintained by the OTB team, a big tarball has been prepared for you.
From the $HOME/OTB directory, do the following:
wget https://www.orfeo-toolbox.org/packages/SuperBuild-archives.tar.bz2 tar xvjf SuperBuild-archives.tar.bz2
The download step can be looooong. Be patient. Go jogging or something.
Compile OTB
Once you have downloaded and extracted the external dependencies, you
can start compiling OTB. From the $HOME/OTB directory, create the
directory where OTB will be built:
mkdir -p SuperBuild/OTB
At the end of the compilation, the $HOME/OTB/SuperBuild/ directory
will contain a classical bin/, lib/, include/ and share/
directory tree. The $HOME/OTB/SuperBuild/OTB/ is where the
configuration and compilation of OTB and all the dependencies will be
stored.
Go into this directory:
cd SuperBuild/OTB
Now we can configure OTB using the cmake tool. Since you are on a
recent GNU/Linux distribution, you can tell the compiler to use the
most recent C++ standard, which can give you some benefits even if OTB
still does not use it. We will also compile using the Release option
(optimisations). The Python wrapping will be useful with the OTB
Applications. We also tell cmake where the external dependencies
are. The options chosen below for OpenJPEG make OTB use the gdal
implementation.
cmake \ -DCMAKE_CXX_FLAGS:STRING=-std=c++14 \ -DOTB_WRAP_PYTHON:BOOL=ON \ -DCMAKE_BUILD_TYPE:STRING=Release \ -DCMAKE_INSTALL_PREFIX:PATH=/home/otb/OTB/SuperBuild/ \ -DDOWNLOAD_LOCATION:PATH=/home/otb/OTB/SuperBuild-archives/ \ -DOTB_USE_OPENJPEG:BOOL=ON \ -DUSE_SYSTEM_OPENJPEG:BOOL=OFF \ ../../OTB/SuperBuild/
After the configuration, you should be able to compile. I have 4 cores
in my machine, so I use the -j4 option for make. Adjust the value
to your configuration:
make -j4
This will take some time since there are many libraries which are going to be built. Time for a marathon.
Test your installation
Everything should be compiled and available now. You can set up some
environment variables for an easier use of OTB. You can for instance
add the following lines at the end of $HOME/.bashrc:
export OTB_HOME=${HOME}/OTB/SuperBuild export PATH=${OTB_HOME}/bin:$PATH export LD_LIBRARY_PATH=${OTB_HOME}/lib
You can now open a new terminal for this to take effect or use:
cd source .bashrc
You should now be able to use the OTB Applications. For instance, the command:
otbcli_BandMath
should display the documentation for the BandMath application.
Another way to run the applications, is using the command line application launcher as follows:
otbApplicationLauncherCommandLine BandMath $OTB_HOME/lib/otb/applications/
Conclusion
The SuperBuild procedure allows to easily install OTB without having to deal with different combinations of versions for the external dependencies (TIFF, GEOTIFF, OSSIM, GDAL, ITK, etc.).
This means that once you have cmake and a compiler, you are pretty
much set. QT4 and Python are optional things which will be useful for
the applications, but they are not required for a base OTB
installation.
I am very grateful to the OTB core development team (Julien, Manuel, Guillaume, the other Julien, Mickaël, and maybe others that I forget) for their efforts in the work done for the modularisation and the development of the SuperBuild procedure. This is the kind of thing which is not easy to see from the outside, but makes OTB go forward steadily and makes it a very mature and powerful software.
Data science in C?
Coursera is offering a Data Science specialization taught by professors from Johns Hopkins. I discovered it via one of their courses which is about reproducible research. I have been watching some of the video lectures and they are very interesting, since they combine data processing, programming and statistics.
The courses use the R language which is free software and is one the reference tools in the field of statistics, but it is also very much used for other kinds of data analysis.
While I was watching some of the lectures, I had some ideas to be implemented in some of my tools. Although I have used GSL and VXL1 for linear algebra and optimization, I have never really needed statistics libraries in C or C++, so I ducked a bit and found the apophenia library2, which builds on top of GSL, SQLite and Glib to provide very useful tools and data structures to do statistics in C.
Browsing a little bit more, I found that the author of apophenia has written a book "Modeling with data"3, which teaches you statistics like many books about R, but using C, SQLite and gnuplot.
This is the kind of technical book that I like most: good math and code, no fluff, just stuff!
The author sets the stage from the foreword. An example from page xii (the emphasis is mine):
" The politics of software
All of the software in this book is free software, meaning that it may be freely downloaded and distributed. This is because the book focuses on portability and replicability, and if you need to purchase a license every time you switch computers, then the code is not portable. If you redistribute a functioning program that you wrote based on the GSL or Apophenia, then you need to redistribute both the compiled final program and the source code you used to write the program. If you are publishing an academic work, you should be doing this anyway. If you are in a situation where you will distribute only the output of an analysis, there are no obligations at all. This book is also reliant on POSIX-compliant systems, because such systems were built from the ground up for writing and running replicable and portable projects. This does not exclude any current operating system (OS): current members of the Microsoft Windows family of OSes claim POSIX compliance, as do all OSes ending in X (Mac OS X, Linux, UNIX,…)."
Of course, the author knows the usual complaints about programming in C (or C++ for that matter) and spends many pages explaining his choice:
"I spent much of my life ignoring the fundamentals of computing and just hacking together projects using the package or language of the month: C++, Mathematica, Octave, Perl, Python, Java, Scheme, S-PLUS, Stata, R, and probably a few others that I’ve forgotten. Albee (1960, p 30)4 explains that “sometimes it’s necessary to go a long distance out of the way in order to come back a short distance correctly;” this is the distance I’ve gone to arrive at writing a book on data-oriented computing using a general and basic computing language. For the purpose of modeling with data, I have found C to be an easier and more pleasant language than the purpose-built alternatives—especially after I worked out that I could ignore much of the advice from books written in the 1980s and apply the techniques I learned from the scripting languages."
The author explains that C is a very simple language:
" Simplicity
C is a super-simple language. Its syntax has no special tricks for polymorphic operators, abstract classes, virtual inheritance, lexical scoping, lambda expressions, or other such arcana, meaning that you have less to learn. Those features are certainly helpful in their place, but without them C has already proven to be sufficient for writing some impressive programs, like the Mac and Linux operating systems and most of the stats packages listed above."
And he makes it really simple, since he actually teaches you C in one chapter of 50 pages (and 50 pages counting source code is not that much!). He does not teach you all C, though:
"As for the syntax of C, this chapter will cover only a subset. C has 32 keywords and this book will only use 18 of them."
At one point in the introduction I worried about the author bashing C++, which I like very much, but he actually gives a good explanation of the differences between C and C++ (emphasis and footnotes are mine):
"This is the appropriate time to answer a common intro-to-C question: What is the difference between C and C++? There is much confusion due to the almost-compatible syntax and similar name—when explaining the name C-double-plus5, the language’s author references the Newspeak language used in George Orwell’s 1984 (Orwell, 19496; Stroustrup, 1986, p 47). The key difference is that C++ adds a second scope paradigm on top of C’s file- and function-based scope: object-oriented scope. In this system, functions are bound to objects, where an object is effectively a struct holding several variables and functions. Variables that are private to the object are in scope only for functions bound to the object, while those that are public are in scope whenever the object itself is in scope. In C, think of one file as an object: all variables declared inside the file are private, and all those declared in a header file are public. Only those functions that have a declaration in the header file can be called outside of the file. But the real difference between C and C++ is in philosophy: C++ is intended to allow for the mixing of various styles of programming, of which object-oriented coding is one. C++ therefore includes a number of other features, such as yet another type of scope called namespaces, templates and other tools for representing more abstract structures, and a large standard library of templates. Thus, C represents a philosophy of keeping the language as simple and unchanging as possible, even if it means passing up on useful additions; C++ represents an all-inclusive philosophy, choosing additional features and conveniences over parsimony."
It is actually funny that I find myself using less and less class inheritance and leaning towards small functions (often templates) and when I use classes, it is usually to create functors. This is certainly due to the influence of the Algorithmic journeys of Alex Stepanov.
Footnotes:
Actually the numerics module, vnl.
Ben Klemens, Modeling with Data: Tools and Techniques for Scientific Computing, Princeton University Press, 2009, ISBN: 9780691133140.
Albee, Edward. 1960. The American Dream and Zoo Story. Signet.
Orwell, George. 1949. 1984. Secker and Warburg.
Stroustrup, Bjarne. 1986. The C++ Programming Language. Addison-Wesley.
Is open and free global land cover mapping possible?
Short answer: yes.
Mid November took place in Toulouse "Le Capitole du libre", a conference on Free Software and Free Culture. The program this year was again full of interesting talks and workshops.
This year, I attended a workshop about contributing to Openstreetmap (OSM) using the JOSM software. The workshop was organised by Sébastien Dinot who is a massive contributor to OSM, and more importantly a very nice and passionate fellow.
I was very happy to learn to use JOSM and did 2 minor contributions right there.
During the workshop I learned that, over the past, OSM has been enriched using massive imports from open data sources, like for instance cadastral data bases from different countries or the Corine Land Cover data base. This has been possible thanks to the policies of many countries which have understood that the commons are important for the advancement of society. One example of this is the European INSPIRE initiative.
I was also interested to learn that what could be considered niche data, like agricultural land parcel data bases as for instance the French RPG have also been imported into OSM. Since I have been using the RPG at work for the last 4 years (see for example here or here), I was sympathetic with the difficulties of OSM contributors to efficiently exploit these data. I understood that the Corine Land Cover import was also difficult and the results were not fully satisfactory.
As a matter of fact, roads, buildings and other cartographic objects are easier to map than land cover, since they are discrete and sparse. They can be pointed, defined and characterised more easily than natural and semi-natural areas.
After that, I could not avoid making the link with what we do at work in terms of preparing the exploitation of upcoming satellite missions for automatic land cover map production.
One of our main interests is the use of Sentinel-2 images. It is the week end while I am writing this, so I will not use my free time to explain how land cover map production from multi-temporal satellite images work: I already did it in my day job.
What is therefore the link between what we do at work and OSM? The revolutionary thing from my point of view is the fact that Sentinel-2 data will be open and free, which means that the OSM project could use it to have a constantly up to date land cover layer.
Of course, Sentinel-2 data will come in huge volumes and a good amount of expertise will be needed to use them. However, several public agencies are paving the road in order to deliver data which is easy to use. For instance, the THEIA Land Data Centre will provide Sentinel-2 data which is ready to use for mapping. The data will be available with all the geometric and radiometric corrections of the best quality.
Actually, right now this is being done, for instance, for Landsat imagery. Of course, all these data is and will be available under open and free licences, which means that anyone can start right now learning how to use them.
However, going from images to land cover maps is not straightforward. Again, a good deal of expertise and efficient tools are needed in order to convert pixels into maps. This is what I have the chance to do at work: building tools to convert pixels into maps which are useful for real world applications.
Applying the same philosophy to tools as for data, the tools we produce are free and open. The core of all these tools is of course the Orfeo Toolbox, the Free Remote Sensing Image Processing Library from CNES. We have several times demonstrated that the tools are ready to efficiently exploit satellite imagery to produce maps. For instance, in this post here you even have the sequence of commands to generate land cover maps using satellite image time series.
This means that we have free data and free tools. Therefore, the complete pipeline is available for projects like OSM. OSM contributors could start right now getting familiar with these data and these tools.
Head over to CNES servers to get some Landsat data, install OTB, get familiar with the classification framework and see what could be done for OSM.
It is likely that some pieces may still be missing. For instance, the main approach for the map production is supervised classification. This means that we use machine learning algorithms to infer which land cover class is present at every given site using the images as input data. For these machine learning algorithms to work, we need training data, that is, we need to know before hand the correct land cover class in some places so the algorithm can be calibrated.
This training data is usually called ground truth and it is expensive and difficult to get. In a global mapping context, this can be a major drawback. However, there are interesting initiatives which could be leveraged to help here. For instance, Geo-Wiki comes to mind as a possible source of training data.
As always, talk is cheap, but it seems to me that exciting opportunities are available for open and free quality global mapping. This does not mean that the task is easy. It is not. There are many issues to be solved yet and some of them are at the research stage. But this should not stop motivated mappers and hackers to start learning to use the data and the tools.
Two misconceptions about open source
There are a couple of ideas which circulate about open source1 projects which I think are misconceptions about how software is developed.
Throw it over the wall
The first one is about criticisms of projects where the developers publish the source code only for released versions instead of maintaining a public version control system. That is, tarballs are made available when the software is considered to be ready, instead of pushing all the changes in real time to services like Github or Bitbucket.
This started to annoy me when a couple of years ago, some bloggers and podcasters started to say that Android is not really open source, since the development is not done in the open. I am not at all a Google fanboy, quite the opposite actually, but I understand that both Google and the individual lone hacker in a basement, may want to fully control how their code evolves between releases without external interferences.
I personally don't do things like this, but if the source code is available, it is open source. It may not be a community project, and some may find ugly to throw code over the wall like this, but this is another thing.
Eyeballs and shallow bugs
The recent buzz about the Heartbleed bug has put back under the spot what Eric S. Raymond called Linus' Law:
Given enough eyeballs, all bugs are shallow.
Raymond develops is as:
Given a large enough beta-tester and co-developer base, almost every problem will be characterized quickly and the fix obvious to someone.
Right after Heartbleed, many voices in the inter-webs took it as a counterexample of Linus' Law. Their reasoning was that since the bug was introduced more than 2 years before, the fact that the source code was open didn't help to catch it quickly.
I think that the argument is flawed if we take into account the 3 steps involved in debugging software:
- Identify that a bug exists: some user (which may be one of the developers) detects a misbehavior in the software. This step may involve characterizing the bug in terms of being able to reproduce the wrong behavior.
- Find the bug: track down the issue until a limited piece of code is identified as containing the source of the problem found.
- Fix the bug: modify the source code in order to obtain the correct or desired behavior.
Usually, the second and third steps are the hardest, but they can't be taken until the bug is detected. After that, Linus' Law comes into play, and the more people looking at the source code, the more likely is for the bug to be found and fixed.
I don't like criticizing Wikipedia, but this time I think that the misunderstanding may come from explanations as the one in the Linux' Law Wikipedia page about Raymond's text.
Footnotes:
I will use the term open source instead of free software because here the important point here is that the source code is available, not the particular license under which it is distributed.
Watching YouTube without a browser
The other day I was curious about how many streaming video sites among those I usually visit had made the move from flash to HTML5.
The main reason is that my virtual Richard Stallman keeps telling me that I am evil, so I wanted to remove the flash plug-in from my machine.
An the fact is that many sites have not switched yet. As far as I understand, YouTube has, at least partially. Therefore, the title of this post is somewhat misleading.
I have been using youtube-dl for a while now in order to download videos from many sites as YouTube, Vimeo, etc. My first idea was therefore to pipe the output of youtube-dl to a video player supporting the appropriate format. Since I usually use vlc I just tried:
youtube-dl -o - <url of the video> | vlc -
This works fine, but has the drawback of needing to manually type (or copy-paste) the URL of the video. So the command line on a terminal emulator is not what I find convenient.
Most of the video URLs I access come to me via e-mail, and I read e-mail with Gnus inside Emacs, I decided that an Emacs command would do the trick. So I put this inside my .emacs:
(defun play-youtube-video (url) (interactive "sURL: ") (shell-command (concat "youtube-dl -o - " url " | vlc -")))
This way, M-x play-youtube-video, asks me for an URL and plays the video. So, when I have an URL for a video on an e-mail (or any other text document on Emacs) I just copy the URL with the appropriate Emacs key stroke and call this command. For convenience, I have mapped it to key binding:
(global-set-key (kbd "<f9> Y") 'play-youtube-video)
So this is good, though not yet frictionless.
Sometimes, the video URL will appear on an HTML buffer, either when I am browsing the web inside Emacs with w3m or when the e-mail I am reading is sent in HTML1. In this case, I don't need to manually copy the URL and I just can ask w3m to do the work.
(defun w3m-play-youtube-video () (interactive) (play-youtube-video (w3m-print-this-url (point)))) (global-set-key (kbd "<f9> y") 'w3m-play-youtube-video)
So far, this has been working fine for me and I don't have the ugly non-free flash plug-in installed, and VRMS is happier than before.
Footnotes:
I use w3m as HTML renderer for Gnus with (setq mm-text-html-renderer 'w3m).
Computers run the world, I run computers, therefore ...
The war on general computation
Although I am not particularly fan of Science Fiction, I follow Cory Doctorow's production because of his views on free culture and free software. He has written many essays about the problems with copyright law and how copyright enforcement is a waste of time. He is himself an example of a creator who is able to make a living making available his work without copy restrictions.
Doctorow has also written about the links between free culture (Creative Commons) and free software, and I don't think I am wrong saying that it all boils down to the same thing.
I recently listened to one episode of the Cory Doctorow podcast about the war on general purpose computation. It was a re-run of the talk he gave at the 28th Chaos Communications Congress in Berlin around last Christmas. The YouTube video with subtitles is available here.
Doctorow has been recently interviewed on CBC about the same topic.
To make a quick synthesis of the talk, we could say that the content industry, in its blind war on copyright infringement, will tend to try to eliminate general purpose computers – that is computers that you can use for whatever you want – and replace them by appliances – that is devices (stripped down computers) which serve one single purpose: content consumption.
At first sight, this may seem some conspiracy theory, but, actually, Apple has started applying the model. For instance, if I write a program for an iPad and I want to sell it to you, the only legal way I have is to go through the Apple Store (and Apple takes 30\%). Otherwise, you have to jailbreak your device. The same kind of trend is coming to Apple desktop and laptop computers. And not much different is the Secure Boot which Microsoft wants to force on computer manufacturers. Google's Chromebooks and other Android tablets limit you ins a somewhat similar way.
Listen to Doctorow's talk to get the full picture. One of the consequences of this war on general purpose computation is that it might even become illegal – I don't think impossible, however – to run free software on most devices available in the market.
The scientist
Since most, if not all, of the science depends in one or another way on computers, for the scientist, this has major implications.
The 2 main pillars of science are independence and reproducibility. These means that a scientist must be able to explain and verify any single result or statement she makes public. In the case of results produced using computer software, being able to look under the hood of the programs used for scientific computation is a fundamental need.
Of course, I am not advocating for the fact that the scientist should code everything herself. This would be too inefficient. But there is when open source software comes to rescue. One can rely on existing tools (libraries, etc.) without having to accept the black box approach of proprietary tools.
I am always astounded to see colleagues using tools for which they don't have the source code. The argument is always that they are being pragmatic, and that theoretical principles about software freedom can be traded against convenience. I can't agree with this.
The day when a bug is detected in one of these software and that you don't have other possibility to get things working correctly than waiting for the new version, you understand that there is a problem.
The day when you can not work because there is a limited number of licenses available in the lab, you understand that there is a problem.
The day you see your students using an illegal version of the software, because they want to improve their skills by working at home, you understand that there is a problem.
And these are only a limited number of real life examples that I have seen around me several times.
Yes, many open source tools lack the degree of polish that proprietary tools have. Some have poor documentation. Some are less user friendly and impose a steep learning curve. The good point is that you can contribute by improving the tool yourself. If you don't have the required skills to do it, you may convince your boss to use the same amount of money she would put into a proprietary software license to hire someone who has the skills to improve the free software you need. After that, do not forget to make your improvements available, so that others benefit from them and consider doing the same.
OK. Enough about work. Let's go home.
The geek dad, or just dad
Most households have at least one computer. Many households have several of them. Nowadays, kids have access to computers from they early age.
Several weeks ago, my children (5 and 7) discovered a web browser in the computer they use for games at home. They also quickly discovered the search engine and the possibility to search on YouTube for videos of their favorite cartoon characters. (In another post I will write about how to explain copyright law to a child who is upset because she can't find on-line the cartoon she wants to watch).
I quickly realized that I hadn't thought about how to filter what they access on the net, so I started looking for something to install.
I know that my ISP proposes a service for that. I know that there are on-line services you can subscribe to. But when it comes to my children, I am not going to give any company the permission to log their web access.
So what I did was installing a free software called DansGuardian which acts as a proxy and filters http requests sent by a browser. It took me 5 minutes to install it and, 10 to understand how to configure it, and 10 more to select the filtering settings I want. OK. I had to read the documentation and mess around with configuration files, but I know exactly what happens, and it's me who looks at the http logs and not an unknown person. Yes, you can say that I am a control freak, and you are right, because, by now, my children are only allowed to use the web browser when their mother or me are with them.
I will call this parental responsibility.
This responsibility includes also teaching critical thinking and giving the freedom to learn. Unfortunately, they don't learn that at school. They don't learn computer skills either. Granted they have computers in the classroom (hey, we are a modern country!), but the teachers are not trained to teach them anything other than to play pseudo-educational games.
The Linux computer my children use has the same kind of software available. They mainly use Tux Paint and GCompris. So what's better with respect to what they have at school?
It's free (as in freedom), so I am confident on being able to run the software on a low end computer if I want to. I can change things that they don't like or that I don't like. For instance, I added their pictures to the set of available Tux Paint stamps. The software is available in many languages, many more than many proprietary software. And this is very useful for kids to learn, even if their mother tongue is a minority one (there are many of them in Europe). Even best, if the language was not available, a parent could translate the software, since all the text messages and the recorded voices are stored in separate files.
This gives a massive freedom to learn, but that's not all. One thing children like very much is taking toys apart. This is not a destructive obsession, but just a need to know how things work. What's the point of playing with software which can't be taken apart to see how it works?
If the war on general purpose computation becomes a widespread reality, our children may not be able to learn to program, or at least, not without spending lots of money in order to buy expensive tools for that. And too bad for those who don't have the money.
They may not be able to put their own pictures on Tux Paint without proving that they own the copyright, and that would be dramatic.

{kind=link}
{kind=link}